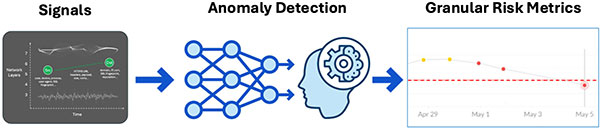
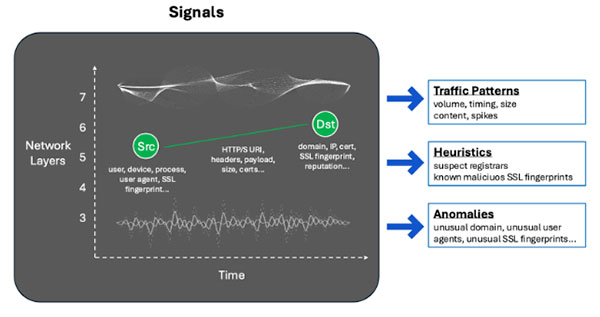
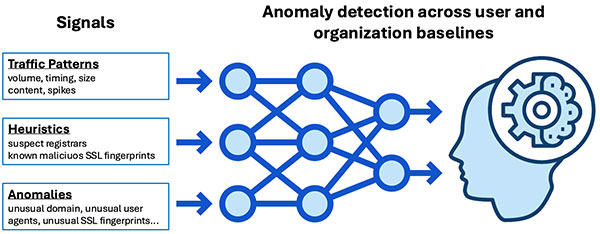
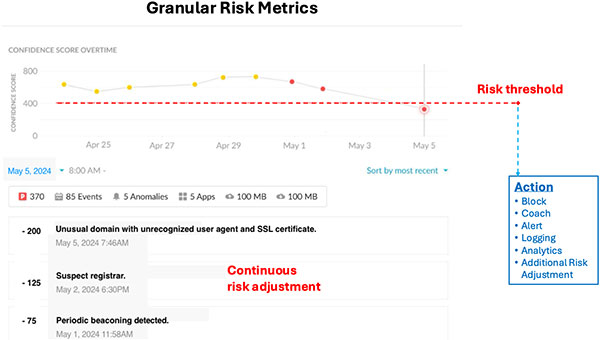
Teoricamente, uma nova abordagem pode ser sólida e, na prática, falhar miseravelmente, e a prova geralmente se resume a dados ou testes. Os fornecedores que fornecem soluções e as organizações que buscam soluções exigem uma abordagem robusta para testar novas ameaças e avaliar soluções. Para obter resultados precisos, é essencial testar com um conjunto de dados diversificado que inclui tráfego malicioso e benigno.
Tráfego
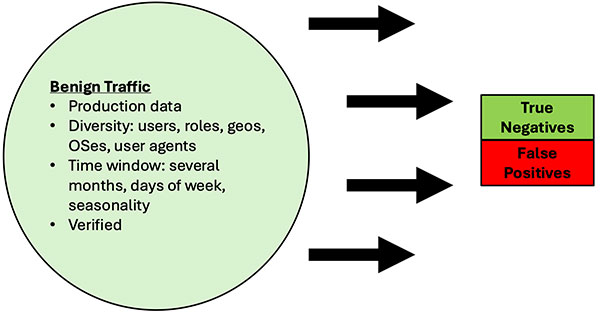
benigno O tráfego benigno deve ser realista, abrangente e semelhante à produção em termos de número de usuários e atividades. Um bom tráfego, geralmente dependente do usuário, deve ser estudado em uma grande amostra de usuários e em um período de tempo razoável. Esse conjunto de dados de teste medirá as taxas de falsos positivos (FP). A principal variação nos conjuntos de dados serão os sinais do cliente, como os aplicativos, os agentes de usuário e os certificados SSL/TLS do cliente que estão sendo usados, os sinais de destino vistos nos domínios/endereços IP de destino e os sinais do padrão de tráfego nos cabeçalhos, carga útil, tamanho e tempo.
A boa notícia é que um bom tráfego benigno é facilmente obtido nas operações diárias dos usuários da organização, enquanto a má notícia é que ele precisa ser validado como benigno. A abordagem prática é amostrar estatisticamente o tráfego benigno até um determinado fator de confiança razoável e, em seguida, passar a maior parte do tempo focando nos alertas da solução de detecção de C2 que está sendo testada, verificando os alertas como verdadeiros positivos ou falsos positivos. Em outras palavras, faça uma amostra inicial e verifique para formar uma linha de base, suponha que o conjunto de dados benigno esteja limpo e, em seguida, prossiga com a identificação de falsos positivos com base nos testes.

Figura 9: Teste benigno de tráfego
Tráfego malicioso
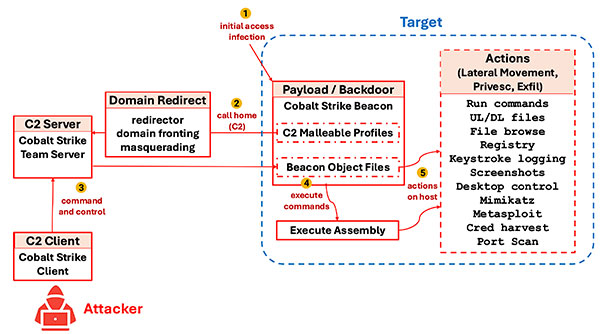
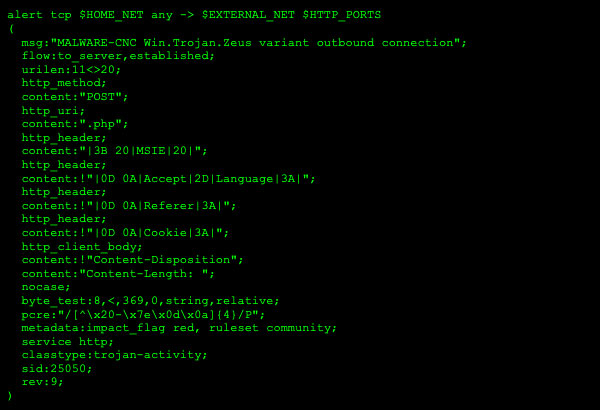
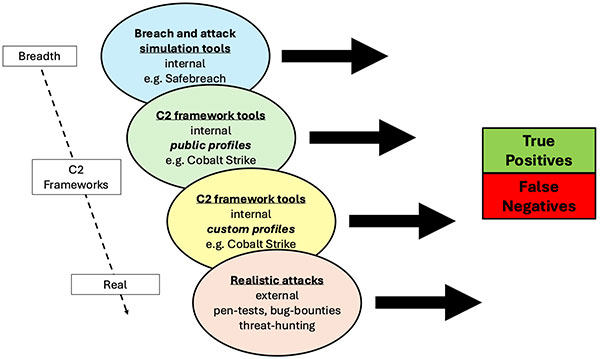
O uso de perfis públicos de ferramentas populares da estrutura C2 fornece uma base sólida para testar tráfego ruim. Esses perfis representam configurações práticas e usadas com frequência que evitam as defesas e ajudam a medir as taxas de falsos negativos (FN). No entanto, deve-se considerar muito a criação de um conjunto de dados representativo de “tráfego ruim”, pois há potencialmente vários níveis na cobertura e no que os conjuntos de dados testam, conforme ilustrado no diagrama a seguir:
Figura 10: Teste de tráfego malicioso
- Ferramentas de simulação de violações e ataques, como o SafeBreach, são excelentes para testes de cobertura e testes repetidos. Seus casos de teste C2 normalmente incluem pelo menos alguma simulação da atividade de estruturas C2. A vantagem é que uma grande variedade de funcionalidades está disponível, incluindo ataques gerais de malware, com GUIs e arquiteturas bem projetadas e procedimentos e relatórios de teste repetíveis. Essas ferramentas podem oferecer uma ampla gama de cenários, incluindo: atividade de baixa lentidão, infraestrutura de IaaS/CSP, tráfego HTTP e não HTTP para tráfego SSL/HTTPS e falsificação de uma variedade de agentes de usuário.
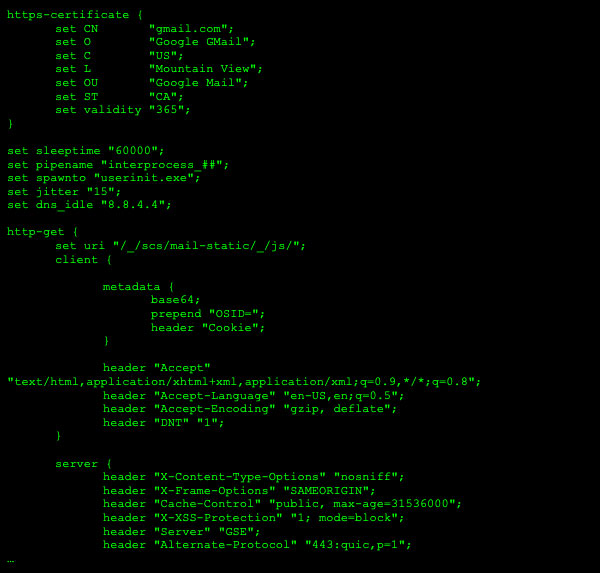
- Ferramentas de estrutura C2 (perfis públicos). O teste aprofundado de estruturas C2 exige um trabalho focado. Uma abordagem é criar um conjunto de dados de teste com base nos perfis públicos específicos das ferramentas da estrutura C2, por exemplo, Cobalt Strike. Esses perfis públicos maleáveis tendem a ser amplamente compartilhados e usados por muitos usuários e agentes mal-intencionados, pois incluem emulações úteis de aplicativos benignos, como o Gmail. Essa abordagem geralmente fornece testes mais abrangentes em torno das estruturas C2 específicas.
- Ferramentas de estrutura C2 (perfis personalizados). A personalização interna dos perfis maleáveis C2 pode fornecer testes ainda mais realistas das estruturas C2. Essas configurações personalizadas podem ser feitas durante as operações internas da equipe vermelha. Isso exige mais trabalho e investimento, pois os operadores da equipe vermelha devem ser fluentes nas ferramentas da estrutura C2.
- Ataques realistas. Os testes mais realistas envolvem testes de caixa preta com programas externos de teste de caneta ou de recompensa por bugs. Nesses cenários, os requisitos do exercício são cuidadosamente construídos para exigir ou incentivar explorações reais de POC que usem ferramentas específicas da estrutura C2 ou qualquer comportamento de sinalização C2, com a ressalva de evitar a detecção por um período de tempo. Os objetivos dos exercícios não são apenas testar os vetores de acesso inicial, que são a norma, mas focar na atividade pós-violação, mostrando a capacidade de instalar uma carga útil de backdoor com a atividade C2 demonstrada. Isso enriquece o conjunto de dados de teste além das estruturas C2 e pode testar o código POC backdoor com comunicações C2 personalizadas, além de ser um excelente teste da resiliência de qualquer ferramenta de detecção a um “invasor” habilidoso que utiliza TTP diferente ou personalizado.
Os testes podem envolver algumas ou várias abordagens, mas devem ser feitas escolhas explícitas sobre como criar, reunir e validar os conjuntos de dados do teste e como medir os resultados esperados. Criar e coletar os conjuntos de dados de teste é muito importante para que os testes possam ser automatizados e facilmente repetidos.
Também é crucial medir métricas completas durante o teste: positivos verdadeiros e falsos, negativos verdadeiros e falsos negativos. Embora a coleta de todas as métricas pareça óbvia, é difícil ser preciso na definição e claro e repetível na metodologia de medição, o que leva a resultados enganosos.
Alvos falsos positivos e falsos negativos
Com as novas ameaças evasivas criadas pelas estruturas C2, qualquer solução de detecção mais recente não terá taxas de FP e FN amplamente aceitas. No entanto, é vital criar metas de FP e FN. Com conjuntos de dados de teste de qualidade conhecidos, linhas de base podem ser criadas para o ambiente atual e usuários/dispositivos, o que permite a criação de metas razoáveis em relação a essas linhas de base.
Por exemplo, suponha que uma organização com apenas um IPS esteja iniciando uma avaliação de novas soluções de detecção de C2 e não esteja claro quais taxas de FP/FN são aceitáveis. A organização ainda pode definir metas razoáveis seguindo uma metodologia de teste, como:
- Crie dados de teste de qualidade para tráfego benigno com base em dados de produção e tráfego malicioso com base, por exemplo, em perfis maleáveis C2 públicos para o Cobalt Strike e validando amostras desses conjuntos de dados manualmente.
- Crie uma metodologia de teste clara e repetível definindo ferramentas de teste e medição.
- Meça todas as métricas (TP/TN/FP/FN) durante o teste
- Teste novas soluções e compare métricas. Por exemplo, o IPS pode ser ajustado especificamente para obter melhores taxas de TP para o tráfego malicioso, mas garantir que as taxas de FP/TN/FN também sejam medidas e validadas. Então, a eficácia de diferentes soluções pode ser avaliada adequadamente, especialmente no impacto total na organização, conforme descrito na seção Impacto abaixo.
- Teste novos conjuntos de dados e compare. Procure personalizar os conjuntos de dados para refletir os ajustes razoáveis feitos por um invasor. Há várias maneiras de fazer isso.
- Por exemplo, ao testar o Cobalt Strike, seus perfis maleáveis C2 podem ser facilmente modificados para emular aplicativos benignos de forma um pouco diferente ou aplicativos benignos completamente novos que são usados na organização específica. Isso pode ser feito detectando o tráfego de saída HTTP/S por meio de um proxy.
- Teste não apenas uma, mas várias ferramentas da estrutura C2, pois elas diferem em recursos e técnicas. Usar uma ferramenta de estrutura C2 diferente também é uma boa mudança, pois sua modelagem de tráfego C2 será diferente.
- Criar uma carga de teste personalizada com suas próprias comunicações C2 codificadas manualmente é outra forma de alterar os conjuntos de dados de teste, mas exige mais tempo e investimento.
Teste de resiliência
Ao testar com novos conjuntos de dados em diferentes soluções, também obtemos informações valiosas sobre a rigidez versus resiliência de diferentes soluções. Neste artigo, levantamos a questão de que as abordagens codificadas e baseadas em assinaturas não são apenas menos eficazes para detectar estruturas C2, mas também são rígidas, resultando em altas taxas de FP/FN e permitem um fácil desvio com mudanças de ataque simples, como mudanças de perfil maleáveis.
A resiliência de qualquer solução pode ser testada garantindo que os conjuntos de dados sejam modificados dentro do razoável (ou seja, permanecendo na mesma categoria de TTP). Em outras palavras, podemos realizar um teste de resiliência realista alterando as comunicações C2 no conjunto de dados de tráfego malicioso usando perfis maleáveis C2 e monitorando as taxas de TP/TN/FP/FN. Vemos como a cobertura varia e também entendemos quais mudanças na solução de detecção precisam ser feitas para manter a cobertura de alvos específicos de TP/TN/FP/FN.
Testar novamente com conjuntos de dados alterados dessa forma é análogo a um invasor alterar seu TTP. Ele avalia a resiliência e a eficácia da nova solução de detecção, pois podemos ver se ela ainda é capaz de detectar alterações na mesma categoria de técnica de ameaça (comunicações C2 por HTTP/S).
Impacto falso positivo e falso negativo
A medição das taxas de FP/FN é boa e permite uma melhoria relativa, mas também precisamos medir ou pelo menos estimar o impacto de FPS e FNs, caso contrário, é impossível avaliar a verdadeira utilidade de qualquer solução de detecção. Em outras palavras, uma taxa de 1% de PF ou uma melhoria de 5% na taxa de PF não tem contexto, a menos que possamos medir o impacto desse 1% ou +5% de alguma forma que faça sentido para os tomadores de decisões orçamentárias de segurança.
Aqui estão duas abordagens que podem ajudar a traduzir as taxas de TP/TN/FP/FN em um impacto mais quantificável:
- Impacto do usuário ao longo do tempo: veja o número absoluto de falsos positivos que são equivalentes às taxas de FP e normalize como uma taxa por usuário ao longo do tempo. Essa é uma medida qualitativa, mas geralmente faz mais sentido do que taxas percentuais ou números absolutos. Por exemplo, em vez de 1% de FPs ou 2.437 falsos positivos, pode ser mais fácil avaliar o impacto de 0,1 falsos positivos por usuário por dia. Se fosse um gateway web seguro, alguém na organização poderia determinar se uma determinada meta de FP é aceitável com base no impacto do usuário ao longo do tempo. Nesse caso, o malware habilitado pela estrutura C2 resulta em violações, e o impacto no usuário é mais caracterizado como tempo de inatividade ou perda de dados por usuário durante um período de tempo. Temos uma chance de N% de perda de $ X por usuário a cada ano. Geralmente, essas são estimativas aproximadas, mas qualquer início é útil, pois pode ser revisado e aprimorado com iterações regulares. Se o impacto for avaliado em termos de usuários ao longo do tempo, fica fácil avaliar as soluções de detecção ou proteção, que geralmente têm como preço o número de usuários por ano.
- Impacto das operações de segurança em termos de tempo, dinheiro e probabilidade de violação. Além do impacto no usuário final, o impacto administrativo deve ser avaliado, especialmente as pessoas de operações que geralmente gastam tempo lidando com alertas de detecção. O tempo gasto em responder a alertas ruidosos pode ser traduzido diretamente em custo salarial FTE. O fator adicional de fadiga de alerta é um impacto real que pode ser estimado em termos de eficácia (tempo para responder) e, mais importante, como a perda de tempo e atenção a ameaças de maior impacto que são perdidas ou não investigadas. Esse último impacto se torna um fator no impacto da violação: é mais provável que as violações ocorram quando as operações de segurança têm muitos falsos positivos para investigar e excluir.
Uma avaliação de impacto geralmente é a única maneira de entender insights cruciais, como o custo real da eficácia da detecção. Por exemplo, uma solução de detecção excessivamente agressiva com uma configuração de FNs baixos e FPs altos é inútil e prejudicial porque as operações de segurança perdem uma quantidade excessiva de tempo respondendo a alertas de baixa fidelidade em vez de se envolverem em atividades de maior alavancagem. Da mesma forma, uma solução de detecção excessivamente conservadora com baixos FPs, mas altos FNs, expõe a organização a um alto risco de uma possível violação, o que pode ser inaceitável do ponto de vista geral da avaliação de risco.
O impacto deve ser estimado e avaliado ao mesmo tempo que as principais métricas de TP/FP/TN/FN.
Testes realistas
Equipe vermelha com humanos, não apenas ferramentas automatizadas de violação ou teste aberto. É altamente recomendável usar não apenas usuários e ambientes de produção para testar soluções de sinalização C2, mas também usar cenários adversários realistas, como testes de caneta ou recompensas por bugs. Ao ajustar os valores e os requisitos das recompensas para mostrar a implantação explícita e as ações bem-sucedidas de pós-exploração dos populares kits de ferramentas do framework C2, podemos tornar o “tráfego malicioso” real e mensurável. Isso pode ser ampliado para qualquer atividade de sinalização C2, incluindo código personalizado para testar a resiliência da solução de detecção, e o requisito de teste deve incluir a demonstração de uma atividade de beacon diária bem-sucedida e a execução de comandos durante uma semana, sem detecção.
Se um pen test externo ou um programa de recompensa por bugs for repetido, as diferenças nas taxas de detecção serão mensuráveis e úteis para avaliar a eficácia e o ROI.
Com uma abordagem rigorosa aos testes, não apenas a eficácia do teste será medida de forma abrangente, mas metas e metas contínuas podem ser criadas em relação a uma linha de base atual/histórica. E, certamente, se os mesmos testes e medições forem realizados para várias soluções, é trivial comparar o desempenho e tomar decisões de compra/implementação.